
Vision-Language Models (VLMs) represent a fascinating intersection of computer vision and natural language processing. The combination of a Vision Encoder with a LLM has sparked interest in the computer vision field to use its capabilities for zero-shot tasks, where using traditional methods lack. Although expensive for large data throughputs, the image + prompt input makes VLMs versatile tools for visual question answering, captioning and various other tasks.
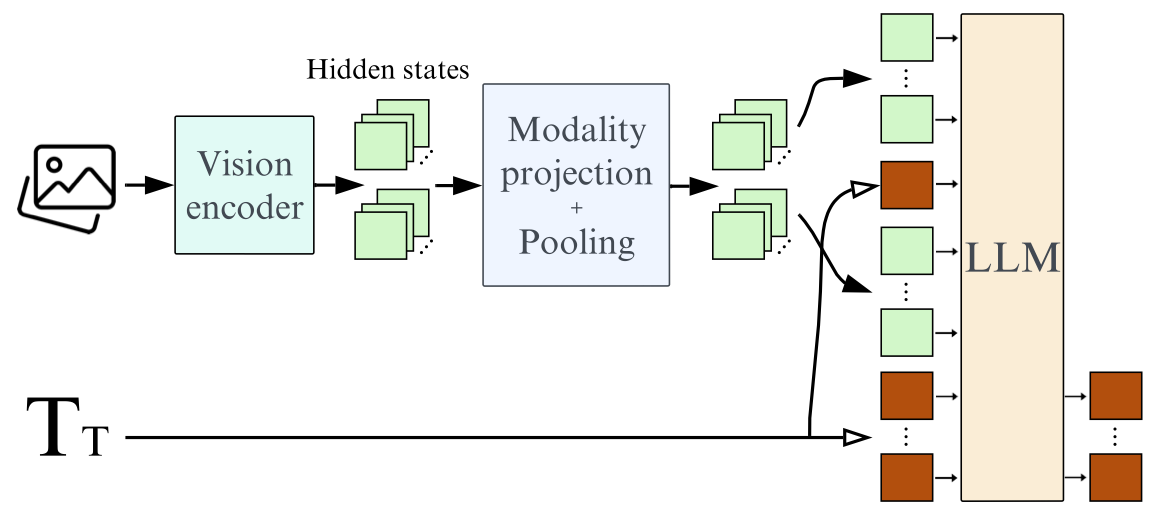
SmolVLM architecture (Image from https://huggingface.co/blog/smolvlm)
While VLMs are a good tool to aid image labelling and curation, they suffer from the same hallucination problems that are prominent in the text domain. Fixing the hallucination problem is the current “million dollars problem”. How can we change the architecture of LLMs to express uncertainty (e.g. by a special token) without it circumventing the training reward? Recent research focuses heavily on mitigating those problems, which seem to be inherent to the transformer architecture, with specialized “hallucination” benchmarks or post-training methods to make the model express uncertainty.
From a training perspective, unique challenges emerge due to the nature of the vision domain data. Large image datasets, such as Laion-5B or ImageNet follow certain distributions to represent the way we depict reality. Why should we have a blue strawberry in our dataset, given that strawberries are red. Having noisy data just degrades performance, right?
Well, let us see where we are right now.
A good example is the work by Vo, Nguyen et. al VLMs are biased. I can recommend reading their full work, where they find that results of all big commercial LLMs are skewed towards the most probable outputs. The chicken has 2 legs.

Image Sample to Test Bias (Image from https://vlmsarebiased.github.io/)
Can you manage to write a prompt to get the LLM to admit that the chicken has 3 legs. I could not. In fact, I even tried cropping the legs from to make the LLM not focus too much on the context, but even Gemini 2.5 Pro hallucinated 4. The paper goes deeper and provides more examples of how trying to disassociate the context and giving hint through language did little to improve the accuracy.
VLM Bias in Research
Given the importance of the problem, there are various research directions that try to mitigate the problem without fine-tuning models.
Steering vectors are a technique used to modify internal activations of the LLM at inference time, without changing the model’s weights. The idea is simple: by comparing the internal representations of two contrasting prompts. Consider the example:
“Paris is the capital of France” vs. “Berlin is the capital of France”
We can isolate a direction in activation space that corresponds to a specific fact (like the identity of a capital city). This direction, or steering vector, can then be added to the model’s activations during inference to influence its outputs. We are essentially “steering” the model toward or away from certain knowledge or behaviors.
In the context of vision-language models (VLMs), steering vectors are only starting to be explored. Recent studies have shown that VLMs encode shared representations across vision and language, and that certain directions in activation space correspond to task-specific behaviors or styles. However, these early applications mostly focus on controlling output format or reducing hallucinations.
A recent paper called “Pixels Versus Priors: Controlling Knowledge Priors in Vision-Language Models through Visual Counterfacts” looks at VLMs often rely too much on language-based knowledge instead of the actual visual input. For example, a model might assume something is a zebra just because it sees stripes, even if it’s not a zebra. The paper introduces the idea of visual counterfactuals—edited images that challenge the model’s assumptions by changing key visual features. By averaging activations of the factuals and counterfactuals, the model relies more on what it actually sees rather than what it expects based on language.
A promising direction for future research is to develop steering techniques that explicitly control this trade-off, allowing us to tune whether the model should trust what it sees or what it knows. This could lead to more controllable, interpretable, and robust vision-language systems to have a more balanced reasoning between pixels and priors. But does that do well in practice?
Mitigating Bias
LLMs are very interesting for (pseudo)-annotation of data, reviewing human annotation from multiple sources or breaking down a computer vision pipeline into smaller steps. In the text-domain, there even exist guides about it. This is a big vision in the computer vision space - what if…we could just give our whole labelling knowledge as a prompt to the LLM?
I did that so you don’t have to:
Generally, choosing the right method is still very task-dependent. Finetuning, in-context learning, prompt engineering - they all bring their own set of ~problems~ solutions. If you are new to this topic, the supervised fine-tuning blog from Google Cloud is a great resource to start.
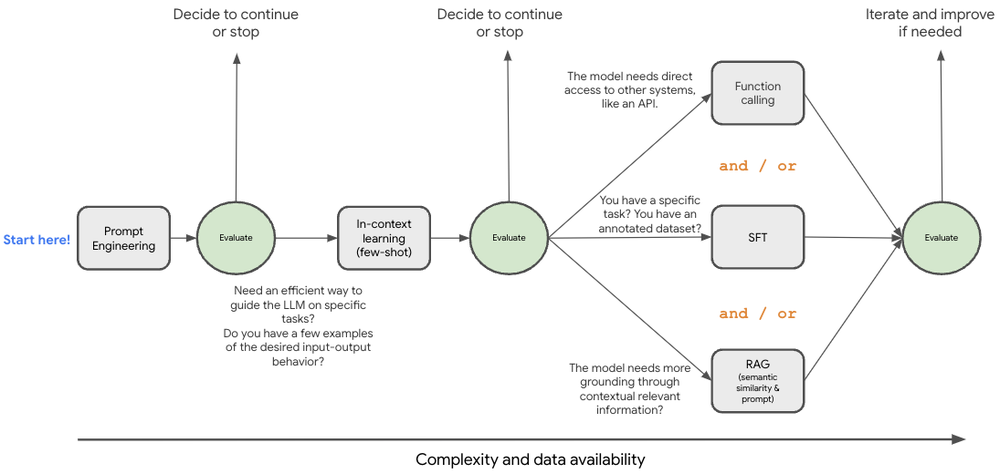
The ML engineer’s decision tree (Image from https://cloud.google.com/blog/products/ai-machine-learning/supervised-fine-tuning-for-gemini-llm)
In my experience, finetuning (only tried using QLoRA!) is the hardest to achieve right. The finetuning dataset has to be carefully curated with all edge cases considered, as the zero-shot performance degrades rapidly. Due to frequent updates on models, fine-tuned models add complexity and retraining overhead which makes them more expensive. Counterfactuals or “negative” samples can help, but at that point it’s mostly easier to stick with more traditional computer vision methods. A problem in practice with counterfactuals is that we have to know which case to expect. In fact, by creating a specific set of counterfactuals, we ironically further add to the bias of the model. Depending on the application, provding counterfactuals can be very challenging. Generally, a task requiring higher zero-shot performance does not do very well.
Another way to mitigate bias is to use another model family to solve or verify the exact same problem. DinoV3, a state-of-the-art vision backbone trained in a self-supervied manner, shows us that training in absence of the text domain works reasonably well.
Ok, we have touched many facettes of self-supervision and bias mitigation. I will tell you, if you are building a computer vision solution in 2025 and resort to VLMs, having human-in-the-loop systems is still king.